Let’s be honest: we are all suffering from AI announcement fatigue. Every other week, some tech giant drops a model that supposedly “changes everything.” We’ve been conditioned to roll our eyes at the hype. But when Google quietly unveiled their new Gemma 4 12B model, something caught my eye that made me stop scrolling. This isn’t just another incremental benchmark bump. It represents a fundamental, radical rethinking of how AI models are engineered from the ground up.
If you’ve ever tried running a capable multimodal model locally on a standard laptop, you know the pain. Your cooling fans scream, your VRAM is instantly choked, and the response generation crawls at a snail’s pace. We’ve accepted this as the tax we pay for “smart” local AI. But Google DeepMind just looked at the bloated architecture of modern AI and decided it was time to cut away the fat. The secret weapon of Gemma 4 12B? It is entirely encoder-free.
The Gemma 4 12B model marks a massive departure from traditional multimodal design by completely eliminating separate encoders.
In this deep-dive, we are going to tear down the hood of this new architecture, look at the elegant mathematics that make it possible, and explore why this might just be the blueprint for the future of local, efficient AI.
The “Frankencode” Crisis: How Multimodal AI Got So Bloated
To understand why the Gemma 4 12B architecture is such a big deal, we first need to look at the messy reality of how current multimodal models work.
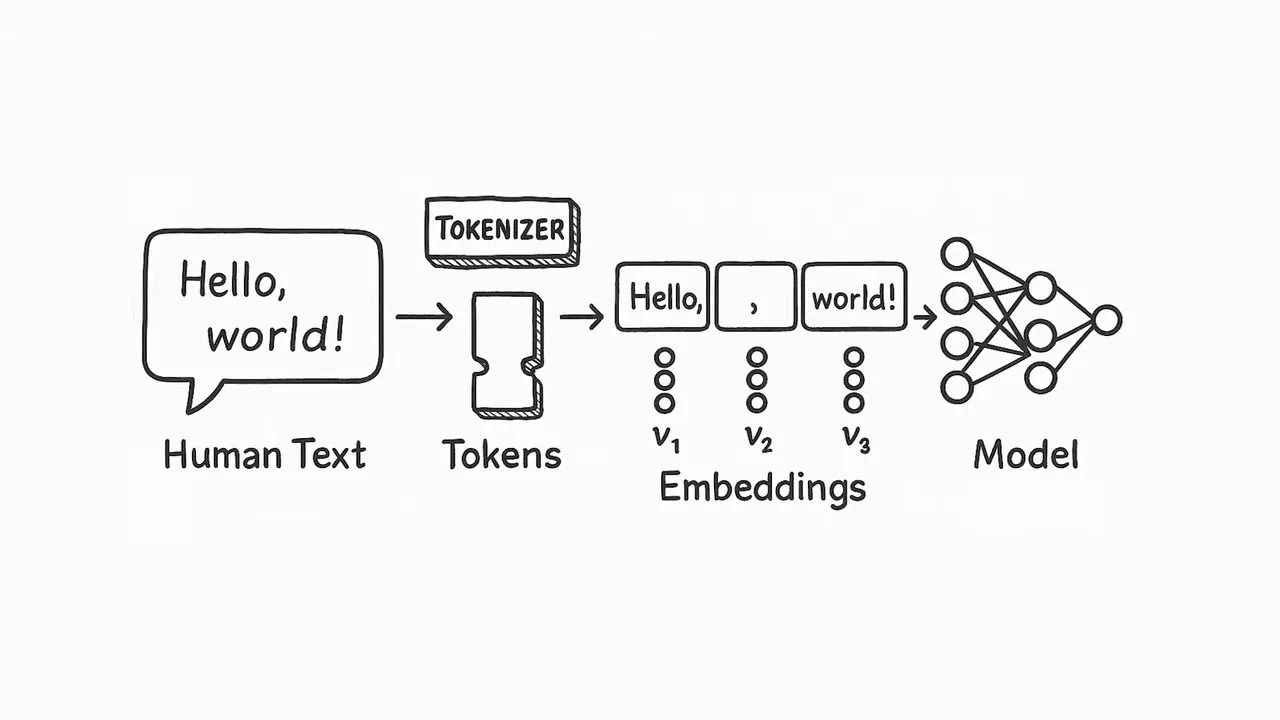
At their core, Large Language Models (LLMs) are blind and deaf. They don’t read text the way we do; they process “tokens”—which are essentially just chunks of text converted into discrete numbers. An LLM has absolutely no native concept of what a pixel in a photo is, or what a soundwave in an audio clip looks like.
![]()
Traditional LLMs are built to process clean numeric tokens, leaving them completely unequipped to handle raw sensory data directly.
To fix this, AI engineers resorted to a sort of architectural “Frankenstein” approach. They took a highly capable text-only LLM and literally taped other independent neural networks onto it.
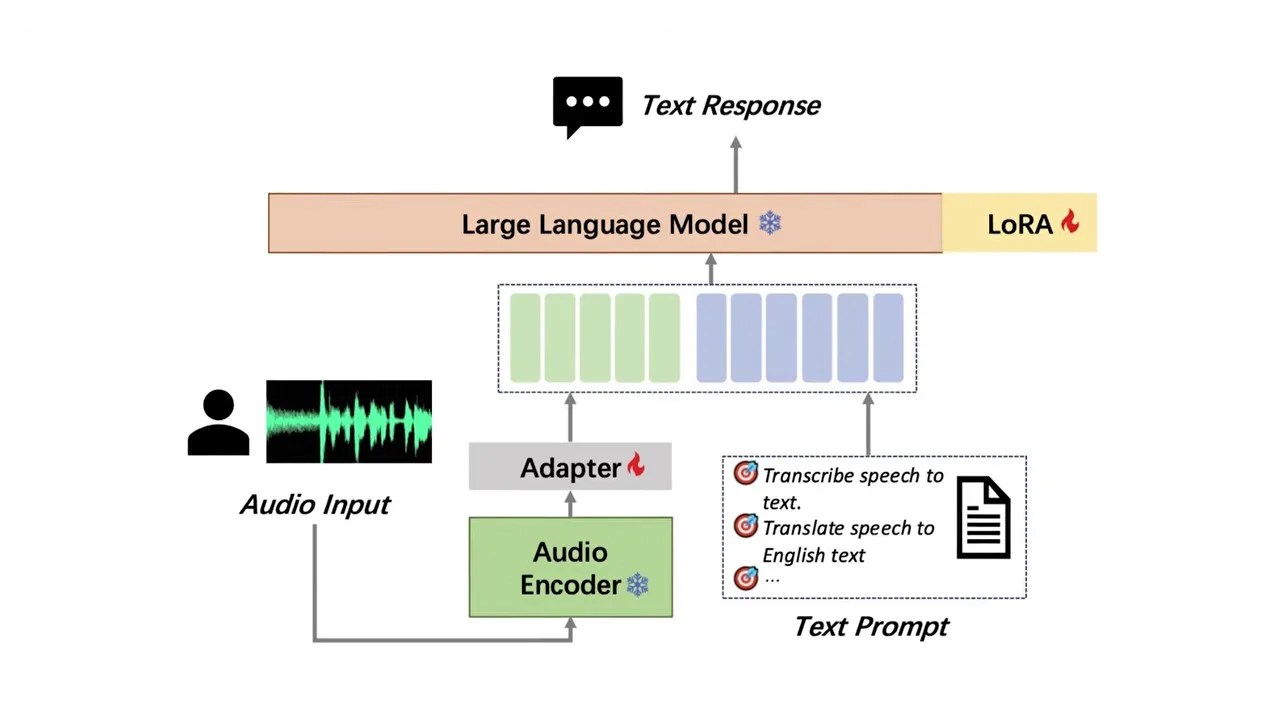
When you upload an image to a typical multimodal AI, the raw pixels don’t go to the main brain first. Instead, they are intercepted by a massive, computationally heavy vision encoder (like a Vision Transformer, or ViT). This encoder spends a huge amount of processing power translating those raw pixels into a high-dimensional mathematical language that the LLM can digest. The exact same thing happens with voice inputs: a separate speech encoder (like OpenAI’s Whisper) has to listen to the audio, map the soundwaves, and translate them before the LLM even gets a turn to “think.”
The standard industry approach: taping heavy, specialized encoder networks to a central text model.
This means that when you run a standard multimodal AI on local hardware, you aren’t just running one model. You are running three separate neural networks simultaneously.
Running multiple independent encoders locally is a surefire way to choke your system’s VRAM and tank performance.
This “taped-together” design is incredibly inefficient. It hogs your graphics card’s VRAM, introduces latency as data is passed between models, and makes local deployment on consumer devices a massive headache.
Here is a quick look at how the traditional approach stacks up against Google’s new streamlined architecture:
| Architectural Feature | Traditional Multimodal Models | Gemma 4 12B (Encoder-Free) |
|---|---|---|
| Vision Processing | Heavy Vision Encoder (e.g., 550M+ parameters) | None (Direct Pixel Feed) |
| Audio Processing | Separate Speech Encoder (e.g., Whisper) | None (Direct Audio Slicing) |
| Local VRAM Footprint | Extremely High (Multiple active networks) | Very Low (Single unified backbone) |
| Cognitive Reasoning | Split between encoders and LLM | Fully centralized within the LLM |
Enter Gemma 4 12B: Deleting the Heavy Vision Encoder
Google DeepMind looked at this structural mess and asked a brilliantly simple question: “Why are we wasting so much computational power on a middleman?”
With the release of Gemma 4 12B, they decided to throw out the entire concept of a heavy vision encoder. They deleted it. Gone.
Instead of passing an image through a massive, half-billion-parameter neural network that tries to “understand” the image before handing it over, Gemma 4 digests the raw pixels directly.
This shift is monumental. To put things in perspective, a standard visual encoder in a modern AI model can easily exceed 550 million parameters on its own. That is 550 million weights that must be loaded into your VRAM, constantly calculating pixel relationships, edges, shapes, and semantic meaning before the actual language model even gets a chance to look at the data.

Traditional vision encoders are incredibly bloated, acting as a massive bottleneck for local AI execution.
Why did traditional models need this? Because a standard encoder is designed to do a lot of heavy cognitive lifting on its own. It features dozens of internal attention layers, all burning compute to figure out what is happening in the image.

Traditional setups require layers of internal attention just to pre-process visual data, duplicating work the LLM is already capable of doing.
DeepMind realized something profound: the main transformer backbone of a modern LLM is already incredibly smart. It possesses massive cognitive capacity and dozens of attention layers of its own. It doesn’t need a separate “brain” to pre-digest the image. The LLM itself is more than capable of handling the visual reasoning natively, provided we can get the raw data into its system in a format it understands.
By stripping away all those redundant thinking layers from the input stage, DeepMind shrunk the visual processing pipeline from 550 million parameters down to a mere 35 million parameters.
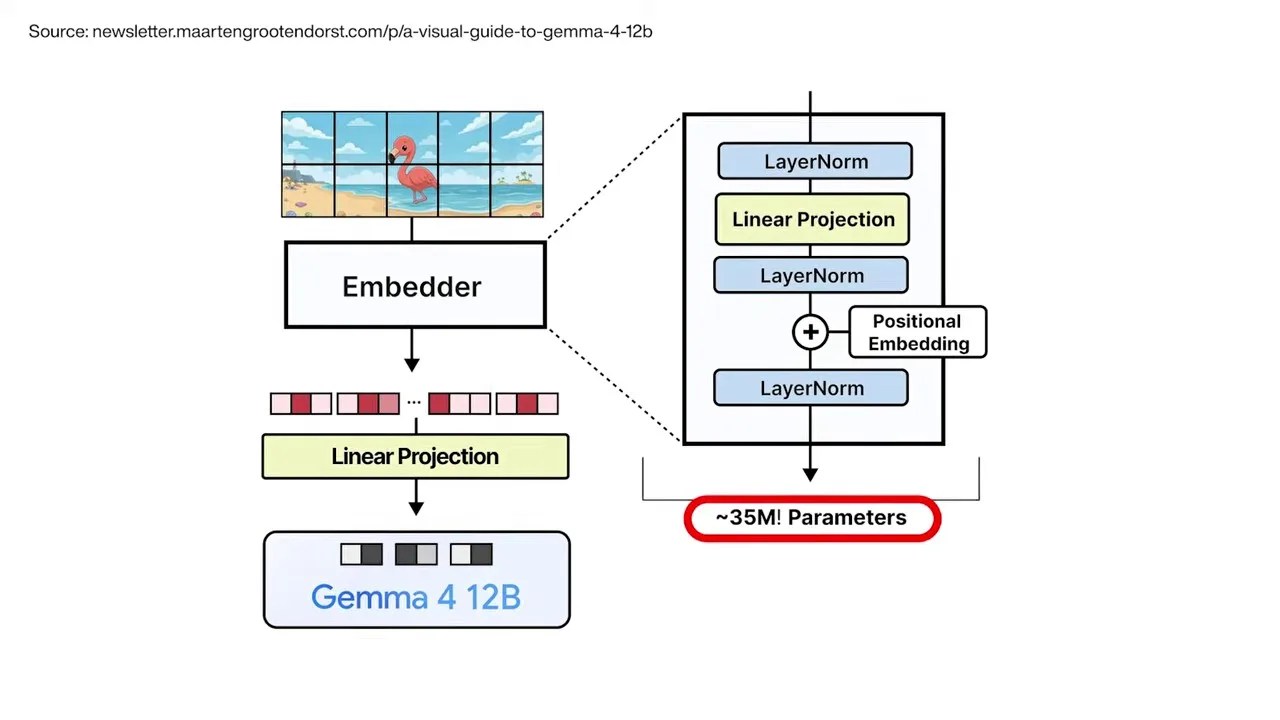
A staggering reduction: from 550 million parameters of redundant computational weight to a lean, static 35-million-parameter mapping layer.
This 35-million-parameter layer doesn’t “think.” It does zero cognitive reasoning. It is essentially a static, mathematical translation layer that reformats raw visual data so it can slide smoothly into the main transformer backbone.
The Math Behind the Magic: 48×48 Patches and Linear Projection
How do you feed raw pixels directly into a text model without an encoder? The engineering behind this is incredibly elegant.
When you feed an image into Gemma 4 12B, the model immediately chops the image up into a grid of tiny, uniform squares measuring 48×48 pixels.
![]()
The first step of Gemma’s encoder-free pipeline: slicing the input image into neat 48×48 pixel patches.
Each of these 48×48 patches is just raw data. Specifically, it is a grid containing exactly 2,304 individual color values (representing the red, green, and blue channels of the pixels).
![]()
A single 48×48 patch is nothing more than a flat grid of 2,304 raw color numbers.
Normally, this raw chunk of numbers would be rejected by the LLM because it doesn’t match the structural format of text tokens. This is where that ultra-lightweight 35-million-parameter layer comes into play. It performs a single, lightning-fast mathematical operation called linear projection.
![]()
Linear projection: a single-step matrix multiplication that reformats raw pixel values instantly.
Using a simple, static grid of connection weights, the model multiplies those 2,304 pixel values in a single step. It stretches and maps them out into a single, clean row of numbers that perfectly matches the native format of the LLM’s text tokens. It does not try to figure out if there is a cat, a car, or a stop sign in the patch; it simply reshapes the raw data container so it can pass through the main model’s front door.
The “Standardized Tray” Analogy: How the Hidden Dimension Swallows Pixels Whole
To really visualize why this works, let’s use an analogy.
Inside every transformer-based language model, there is a strict formatting rule known as the hidden dimension. Think of this hidden dimension as a standardized tray size in a highly automated cafeteria.

Think of the LLM’s hidden dimension as a standardized tray. Everything entering the model must fit this exact shape.
Whether you are feeding the model the word “apple,” a piece of Python code, or a question mark, everything must be converted and placed onto this standardized “tray” (a specific, massive list of numbers) so that the mathematical equations inside the transformer can process it.
If you try to throw a raw, square 48×48 grid of pixels directly into the system, the machinery jams. The dimensions don’t match the tray.
The 35-million-parameter mapping layer acts as the ultimate tray-packer. It takes that raw, square grid of 2,304 color values, does a single physical stretch, and lays it out flat so it fits the standardized tray perfectly.
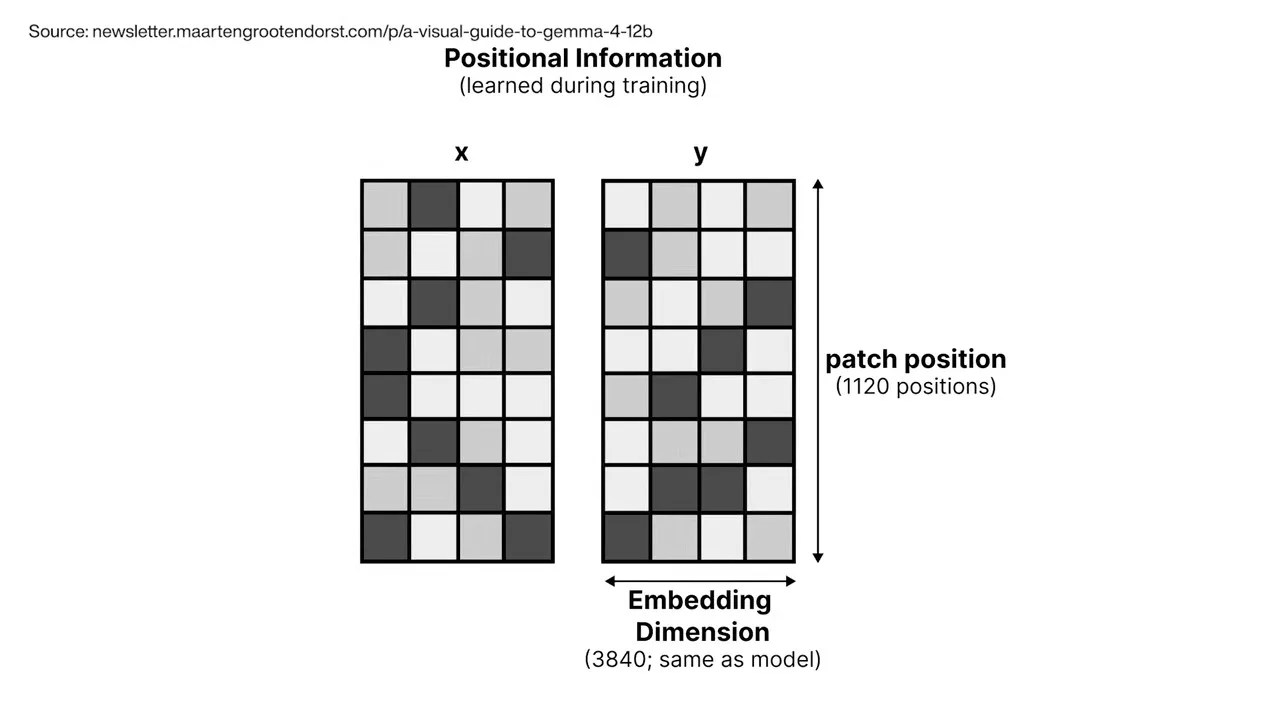
The mapping layer does no thinking; it is a mechanical formatter that preps raw sensory data for the main transformer.
Because this layer does zero analytical thinking, it uses virtually no processing power. It frees up your VRAM and allows the main, highly optimized LLM backbone to handle the actual visual reasoning natively. The visual data is processed alongside text tokens using the exact same attention mechanisms, making the multimodal understanding incredibly cohesive.
Slicing Soundwaves: The Audio Encoder Gets the Axe Too
If you thought what they did with vision was clever, wait until you see how they handled audio. DeepMind applied the exact same philosophy to speech, making the architecture even simpler.
To eliminate the heavy, power-hungry speech encoders that typically translate voice inputs, Gemma 4 takes a raw 16 kHz audio signal and slices it up into continuous, bite-sized 40-millisecond frames.

Audio signals are sliced into tiny, continuous 40ms blocks, with each block containing 640 floating-point numbers.
Each little 40ms frame contains exactly 640 floating-point numbers describing the physical shape of the soundwave. The model takes those 640 numbers and runs them through a simple projection layer—identical in concept to the vision projection layer—mapping them straight into the language model’s input space.
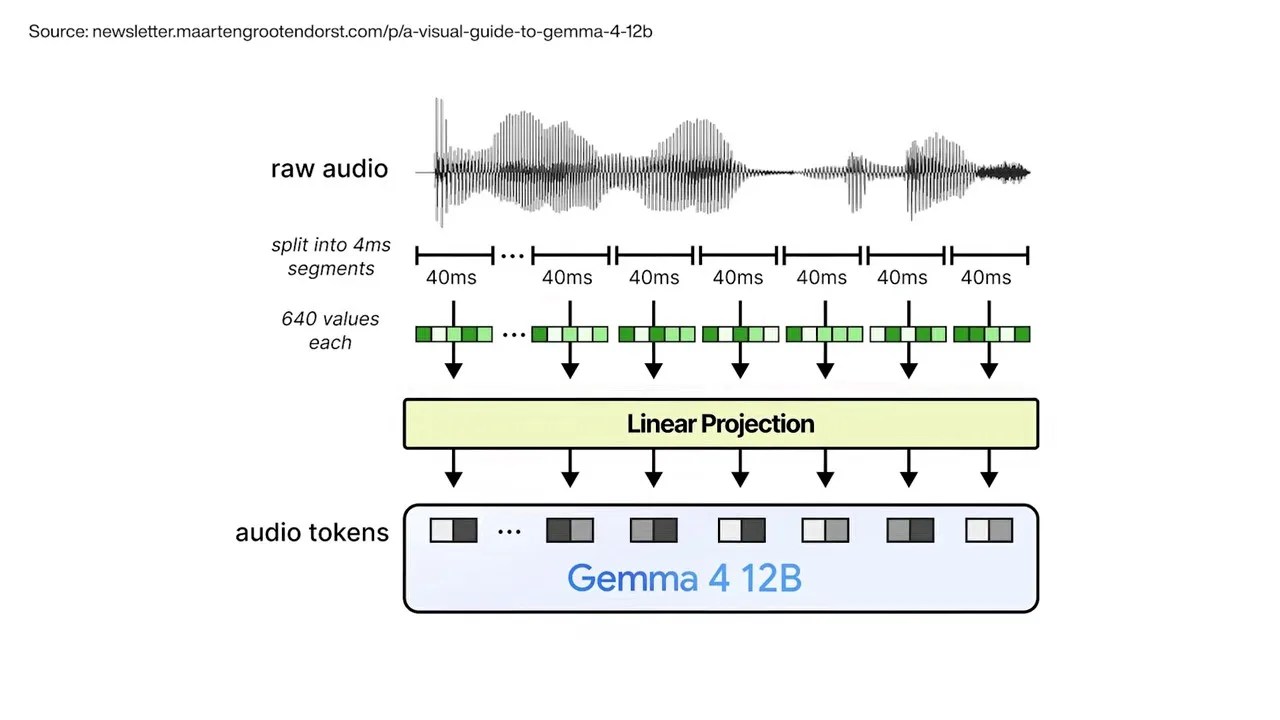
By mapping raw audio blocks directly into the input space, Gemma 4 processes sound as natively as it processes text.
The soundwaves slide right into the transformer alongside your text prompt. No speech-to-text translation step, no heavy intermediate model, and no wasted VRAM. The main LLM backbone listens, reads, and sees using the exact same unified, elegant pipeline.
Why Audio as Text is an Absolute Game-Changer
Because sound is inherently chronological—just like a sentence is a sequence of words—the transformer treats these mapped audio frames exactly like text tokens. To the core model, a 40-millisecond block of sound waves looks identical to a continuous stream of written words.
This deep, native integration is where the magic happens. Because the visual, auditory, and textual data all live in the exact same mathematical space, the 12-billion-parameter model can handle live transcription, real-time translation, and advanced text formatting in a single forward pass. You don’t have to load a separate speech recognition network, wait for it to output text, and then feed that text to the LLM. Gemma 4 12B does it all at once, saving massive amounts of memory and compute.
Local Hardware Triumph: Benchmarks and Multi-Token Prediction
By stripping away all the redundant encoder bloat, Google DeepMind managed to pack top-tier reasoning capabilities into a remarkably tiny footprint. When we look at the raw benchmarks, this streamlined design allows the 12-billion-parameter model to punch far above its weight class, getting incredibly close to the performance of much larger 26-billion-parameter models.

The lean architecture of Gemma 4 12B allows it to rival models nearly twice its size on core multimodal benchmarks.
For those of us obsessed with local hardware, this is a massive win. A model of this caliber can easily fit on a standard modern laptop with 16 GB of VRAM or more. But Google didn’t stop at just shrinking the model’s footprint; they also tackled generation speed.
Out of the box, Gemma 4 12B includes native multi-token prediction drafters. Instead of predicting just one word at a time in a single sequence, the model can predict multiple tokens simultaneously.
Native multi-token prediction allows for blistering local inference speeds without forcing users to rely on lossy quantization techniques.
This means you get blazing-fast local inference speeds without being forced to heavily compress or quantize the model, which usually degrades the AI’s intelligence and reasoning quality.
Real-World Testing: Official Bloat vs. Lean Third-Party Engines
Of course, paper specs are one thing—how does it actually perform in the real world? To find out, I put it to the test on my local M2 MacBook Pro equipped with 24 GB of unified memory.
I have to say, my journey started with some classic Google-style friction. I attempted to use Google’s official AI Edge Gallery application to test the model. To put it bluntly: the app is an absolute mess. Every single time I tried to upload an image and ask for an analysis, the application crashed instantly, throwing cryptic, random errors.
Google’s official AI Edge Gallery application proved to be highly unstable, failing to process basic image queries.
It’s classic Google—brilliant research and groundbreaking architecture, let down by buggy, half-baked developer tools. Thankfully, we don’t have to rely on Google’s official software to run their open models.
Instead, I turned to OMLX, an outstanding, highly optimized framework designed specifically for running AI models locally on Apple Silicon. I loaded up an 8-bit quantized version of Gemma 4 12B, completely cut off my internet connection to ensure a 100% offline test, and threw some real-world visual challenges at it.
Real-Time Local Demos: Airport Departures and Blurry TV Shows
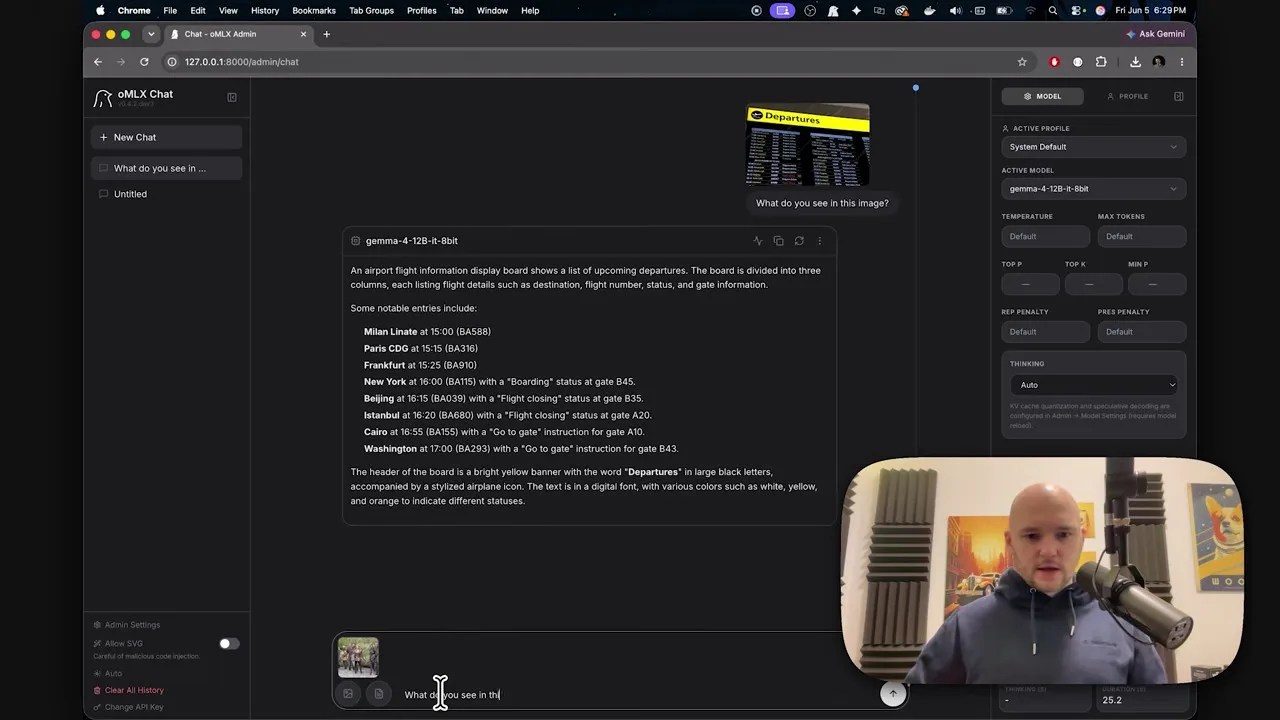
For the first test, I uploaded a busy, text-heavy screenshot of an airport departure board. I asked a simple question: “What do you see in this image?”
The speed was absolutely jaw-dropping. The moment I hit enter, the model immediately began parsing the image. It didn’t stutter or freeze; it smoothly and rapidly extracted the flight numbers, destinations, and gate statuses in real time.
Running completely offline on an M2 MacBook Pro via OMLX, the model parsed a complex, text-heavy image with zero latency.
Next, I wanted to test its ability to handle low-quality, low-contrast visual data. I fed it a blurry, dark screenshot from the TV show Vikings and asked the same open-ended question.
Once again, Gemma 4 12B blew me away. It didn’t just recognize that there were people in the image; it successfully identified the gritty aesthetic, the period-specific clothing, and correctly associated the visual style with the show.
Even with blurry, dark, and low-contrast inputs, the unified transformer backbone handled the visual reasoning flawlessly.
Watching this run locally, offline, and at such speeds made one thing abundantly clear: this is the best local image reasoning model I have ever tested in this size category.
The Future is Unified, Local, and Lean
Google DeepMind has effectively proved a vital thesis: a single, unified language backbone is smart enough to handle vision and sound natively.
By throwing out the heavy, redundant vision and speech encoders, they have opened up a brand-new path for local AI. We no longer need to accept bloated, multi-network setups that choke our VRAM just to get multimodal capabilities. Gemma 4 12B shows that with elegant engineering and smart, single-step mathematical mapping, we can have highly efficient, blazing-fast, and incredibly smart multimodal reasoning directly on consumer edge devices.
The era of the bloated AI encoder is officially drawing to a close, and the era of truly native, unified multimodal models has begun.
Frequently Asked Questions
Why is an encoder-free architecture like Gemma 4 12B better for local devices?
Traditional multimodal models require you to run three separate neural networks simultaneously (the LLM, a vision encoder, and a speech encoder), which heavily consumes VRAM and slows down performance. Gemma 4 12B eliminates these heavy encoders, reducing the visual processing pipeline from 550 million parameters to a lean 35 million parameters. This drastically lowers the VRAM footprint and allows the model to run incredibly fast on standard laptops.
What does the 35-million-parameter mapping layer in Gemma 4 actually do?
This layer does zero cognitive reasoning or analysis. Instead, it acts purely as a mathematical format converter. It takes raw 48×48 pixel patches (2,304 color values) and performs a single-step linear projection to stretch and reshape the data so it matches the standardized “hidden dimension” format of the LLM’s text tokens. The actual “thinking” and visual reasoning are then performed natively by the main transformer backbone.
How does Gemma 4 12B process audio without a speech encoder?
The architecture slices raw 16 kHz audio signals into continuous 40-millisecond frames, with each frame containing 640 floating-point numbers representing the soundwave. These numbers are projected directly into the language model’s input space using a simple projection layer. Because audio is sequential, the transformer treats these sound frames exactly like text tokens, allowing for native transcription and translation in a single forward pass.



