Let’s be honest: most AI news these days feels like a repetitive echo chamber. We get slightly faster models, slightly larger context windows, and a lot of marketing fluff. But every once in a while, something drops that genuinely shifts the ground beneath our feet. That moment is now. Google DeepMind AlphaProof has quietly redefined how machines “think,” tackling problems that have stumped the world’s most brilliant human minds for decades.
If you only look at the raw headlines, you might think this is a failure. An AI tried to solve unsolved mathematical mysteries and failed 95.7% of the time. But in the world of high-level mathematics, that failure rate is a spectacular, historic victory. Let’s peel back the layers of how this system actually works, why its architecture is so radically different, and why the future of AI isn’t just about making models bigger—it’s about building smarter loops around them.
The Hungarian Legend and the 95.7% “Failure”
To understand the scale of what we are dealing with, we have to talk about Paul Erdős. He was a legendary, eccentric Hungarian mathematician who spent his life wandering the globe, leaving behind a trail of over a thousand unsolved mathematical problems. These aren’t high school algebra questions; these are deep, structural puzzles that have resisted the efforts of the world’s finest minds for over half a century.

Paul Erdős, the legendary Hungarian mathematician who challenged generations with his unsolved problems.
When DeepMind AlphaProof was set loose on a subset of 350 of these legendary Erdős problems, it failed to solve 341 of them. It only solved nine. On paper, a 95.7% failure rate looks terrible. But in reality? It is absolutely stunning.

The metrics: AlphaProof solved 9 incredibly complex, decades-old problems at a highly cost-effective rate.
Each of those nine solved problems represents a mathematical peak that no human had ever scaled before. And the system did it at a cost of just a few hundred dollars per problem. To put this in perspective, think about how quickly AI math capabilities have evolved. Just four years ago, GPT-3 struggled with basic arithmetic. Two years ago, high school competition math was a major hurdle. Today, we are looking at systems solving decades-old, open-ended research problems.
![]()
The rapid, almost vertical trajectory of AI math capabilities over the last four years.
As Dr. Károly Zsolnai-Fehér of Two Minute Papers often reminds his audience: “Do not look at where we are. Look at where we will be two more papers down the line.” The trajectory is clear as day.
The Secret Weapon: Lean and Formal Verification
Why can’t you just ask a standard LLM like GPT-4 or Claude to solve an unsolved math problem? Because they hallucinate. They write beautiful, highly convincing mathematical prose that is completely, fundamentally wrong. They lack a mechanism for ground truth.
To bypass this limitation, DeepMind forced AlphaProof to speak in Lean.
An example of Lean, a formalized language that allows computers to mathematically verify proofs with absolute certainty.
Lean is a formalized mathematical programming language. Think of it as a compiler for math. If you write a proof in Lean, the software can check every single logical step with mathematical certainty. There is no room for “vibe-based” reasoning or hallucination. Either the proof compiles and is 100% correct, or it doesn’t.
The Tournament of Errors: ELO Ratings for Broken Proofs
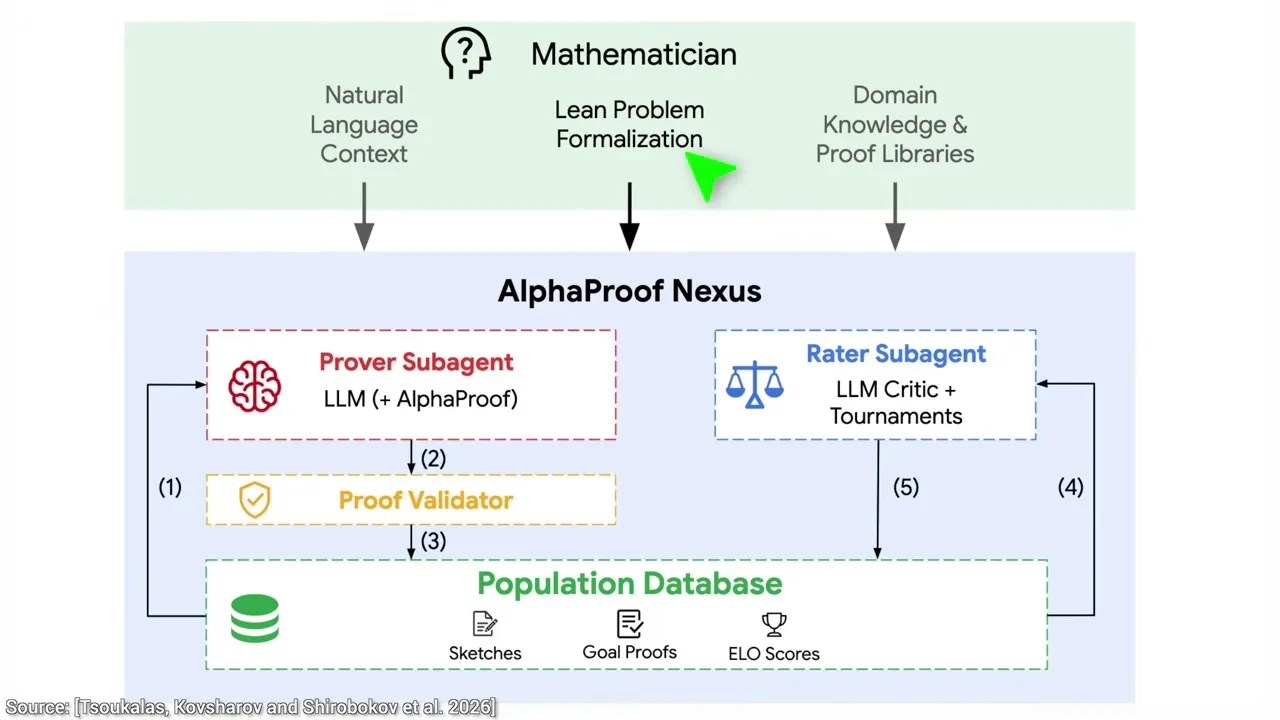
Unpacking DeepMind AlphaProof: The Architecture of the Loop
So, how does the system actually find these proofs? It doesn’t just guess once and give up. It sets up an internal evolutionary game. A mathematician translates the problem into Lean, leaving the proof blank. Then, the AI generator attempts to fill in the blanks. Naturally, it fails because the problem is incredibly difficult.
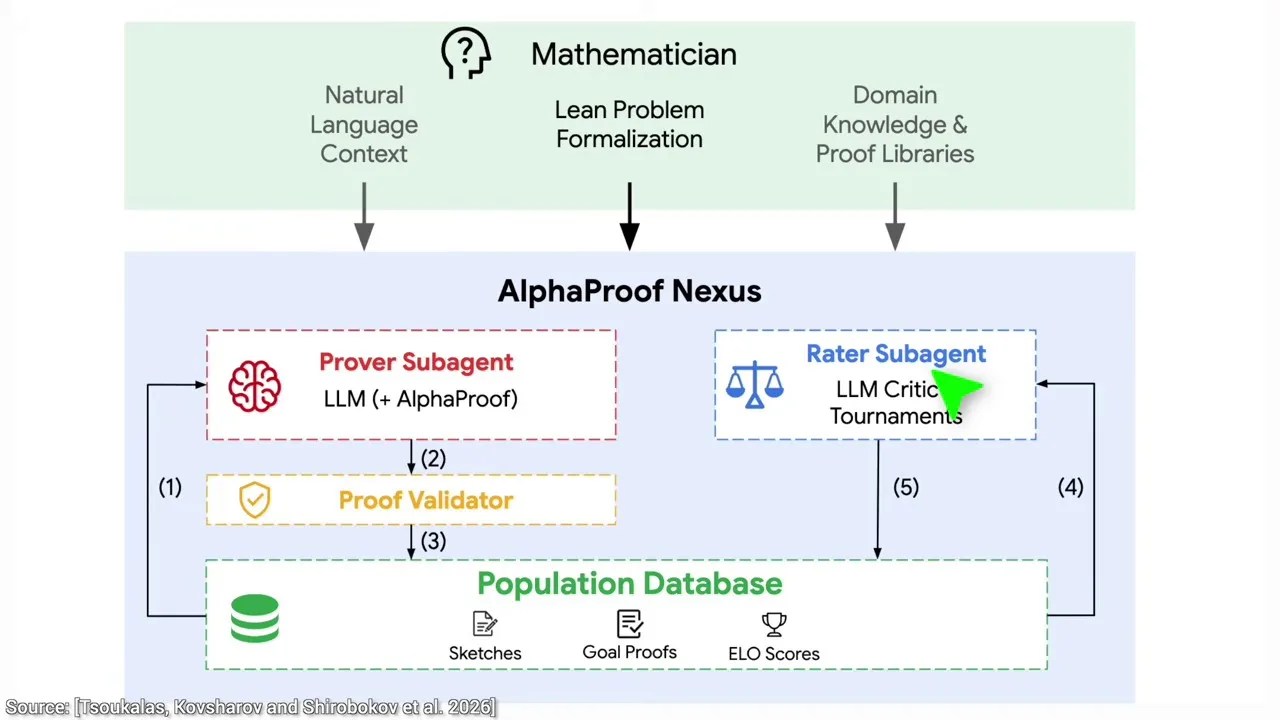
The core architecture: A generator proposes solutions, while a cheaper judge AI evaluates and ranks them.
This is where the genius of the system lies. DeepMind introduced a cheaper “judge” AI that looks at the failed attempts. It doesn’t need to know the correct answer (since nobody does). Instead, it reads two incorrect solutions and decides which one is slightly less terrible.
![]()
The tournament loop: Failed proofs are ranked using an ELO rating system, allowing the model to iteratively build on its best mistakes.
This creates a competitive tournament. Each incorrect proof is assigned an ELO rating—the very same rating system used in chess (coincidentally invented by another Hungarian, Arpad Elo). The system then starts its next round of generation, not from scratch, but from the highest-rated “bad” solution. By iteratively building on its best mistakes, the system eventually finds a path that compiles perfectly in Lean.
The Great Shift: Intelligence in the Loop, Not the Model
This architecture represents a profound philosophical shift in AI development. For years, the industry’s main goal was simple: make the core model smarter. Feed it more data, give it more parameters, and hope it figures out how to reason.
Now, the strategy has flipped. We don’t necessarily need a smarter model; we need a tighter, more rigorous harness around it.

The paradigm shift: Moving from raw model scale to structured, agentic loops.
By surrounding an unreliable, hallucination-prone LLM with a strict mathematical verifier and an evolutionary feedback loop, we get a highly reliable system built out of unreliable parts. The intelligence is no longer just in the weights of the neural network; it is in the loop itself.
| Feature | Traditional LLM Prompting | Loop-Based Reasoning (AlphaProof) |
|---|---|---|
| Accuracy Guarantee | Low (Prone to plausible-sounding hallucinations) | Absolute (Verified by Lean compiler) |
| Methodology | Single-pass generation / basic chain-of-thought | Iterative evolutionary tournament with ELO ranking |
| Computation Cost | Very low (seconds of compute) | Moderate to high (hours/days of search per problem) |
To build and optimize these complex loops, engineers are relying on advanced tracing and evaluation toolkits. These tools allow developers to visualize data flows, debug multi-step agentic systems, and measure performance gains over thousands of iterations.
Modern developer toolkits allow engineers to trace, debug, and optimize complex reasoning loops.
The Hard Truths: Selection Bias and the Size Barrier
As exciting as this is, we must look at the results with a healthy dose of scientific skepticism. There are two major caveats that the mainstream media often overlooks.
First, there is a clear selection bias in the dataset. Out of the 1,200 open problems left by Erdős, DeepMind only tested AlphaProof on 350.

A key limitation: The tested subset consisted of problems that were easier to formalize in Lean.
They chose these 350 because they were the easiest to translate into Lean’s formal code. Translating abstract, high-level math into a formalized computer language is a massive bottleneck that still requires human experts. We are not yet at the stage where an AI can read a paper in plain English and formalize it automatically.
Second, model size still matters immensely. When DeepMind tried this exact same loop technique with smaller, lightweight models, the results were brutal: they solved absolutely zero problems.
The size barrier: Smaller models failed to solve a single problem, proving that a powerful core LLM is still mandatory.
This tells us that while the loop is incredibly powerful, it cannot compensate for a lack of core capability. You still need a massive, highly capable model at the center of your loop to generate the initial sparks of intuition. The loop simply fan those sparks into a flame.
The Road Ahead
Despite the limitations, what DeepMind has achieved here is nothing short of historic. They took an unreliable, creative AI, plugged it into a relentless mathematical judge, let it fail thousands of times, and came out with solutions to problems that human geniuses couldn’t crack for half a century.
We are witnessing a fundamental shift in computer science. The era of just training bigger models is giving way to the era of designing brilliant, self-correcting harnesses. And that is a very exciting world to live in.
Frequently Asked Questions
Why is a 95.7% failure rate considered a success for AlphaProof?
Because the problems it was trying to solve are famous, unsolved mathematical mysteries that have remained open for over 50 years. Solving even one of these problems is a major academic achievement. Solving nine of them automatically is unprecedented.
What role does Lean play in this AI system?
Lean acts as an absolute validator. It is a formalized programming language for mathematics. Because Lean can compile and verify mathematical proofs with 100% certainty, it completely eliminates the risk of AI hallucination.



